
🎓 Top 15 Udemy Courses (80-90% Discount): My Udemy Courses - Ramesh Fadatare — All my Udemy courses are real-time and project oriented courses.
▶️ Subscribe to My YouTube Channel (178K+ subscribers): Java Guides on YouTube
▶️ For AI, ChatGPT, Web, Tech, and Generative AI, subscribe to another channel: Ramesh Fadatare on YouTube
Introduction
Apache Kafka has become the go-to distributed messaging system for handling real-time data streams in large-scale, event-driven systems. Whether you’re applying for a backend, big data, or DevOps role, Kafka is a must-know technology.
In this article, we’ve compiled the top 25 Apache Kafka interview questions and answers, suitable for freshers, intermediate, and experienced developers. Each question comes with a clear explanation and real-world context to help you ace your Kafka interview.
✅ 1. What is Apache Kafka?
Apache Kafka is a distributed, fault-tolerant messaging system used to build real-time data pipelines and stream processing systems. It’s designed to handle high throughput and low-latency data communication between producers and consumers.
✅ 2. What are the key components of Kafka?
- Broker: A Kafka server that stores data and serves client requests. Kafka clusters consist of multiple brokers.
- Producer: A client that sends (publishes) messages to Kafka topics.
- Consumer: A client that reads (consumes) messages from Kafka topics.
- Topic: A category or feed name to which records are sent by producers. Topics are partitioned and replicated for scalability and fault tolerance.
- Partition: A division of a topic. Each partition is an ordered, immutable sequence of records.
- Offset: A unique identifier for each record within a partition, representing its position.
- Consumer Group: A group of consumers that work together to consume messages from a topic.
- Zookeeper — Coordinates brokers and maintains cluster metadata (being replaced by KRaft in newer versions).
✅ 3. What is a Kafka Topic?
A Kafka Topic is a logical name that categorizes a stream of records. Producers publish messages to topics, and consumers subscribe to them.
Topics can be partitioned and replicated for scalability and fault tolerance.
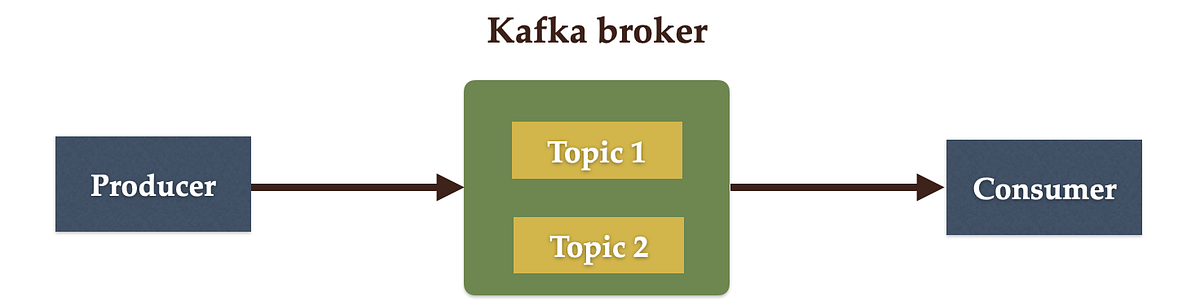
✅ 4. What is a Kafka Partition?
A partition is a sub-topic or shard of a topic. Each partition is an append-only log, and messages in a partition are ordered.
Kafka topics are divided into a number of partitions, which contain records in an unchangeable sequence.
Kafka Brokers will store messages for a topic. But the capacity of data can be enormous and it may not be possible to store in a single computer. Therefore it will be partitioned into multiple parts and distributed among multiple computers since Kafka is a distributed system.
Kafka uses partitions for:
- Load balancing
- Parallel processing
- Scalability
The following diagram shows that Kafka’s topic is further divided into a number of partitions:
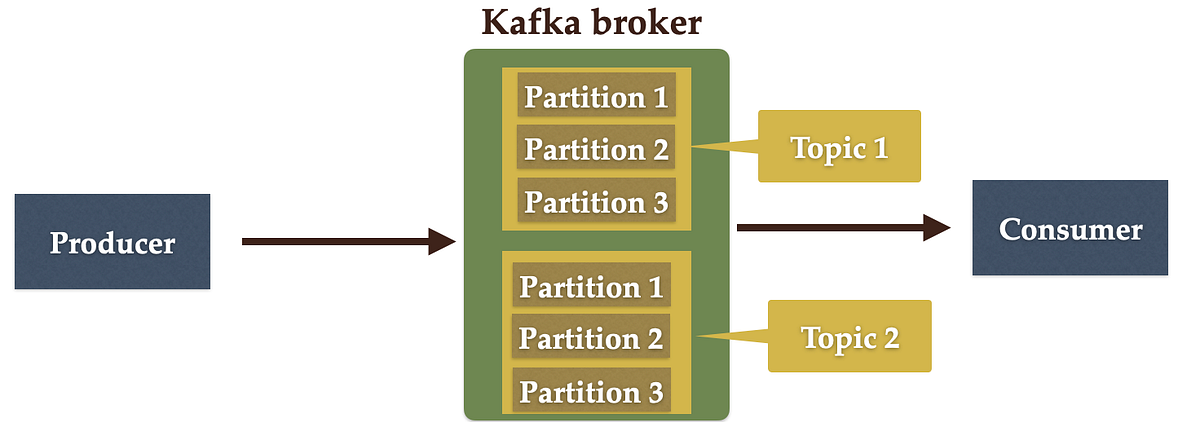
✅ 5. What is a Kafka Consumer Group?
A Kafka Consumer Group is a group of consumers that work together to read data from a Kafka topic.
Each consumer in the group reads from a different partition, ensuring parallel processing and load balancing. If the number of consumers exceeds the number of partitions, some will remain idle. All consumers in the group share the same group ID, and Kafka ensures that each partition is read by only one consumer in the group at a time.
✅ 6. What guarantees does Kafka provide?
Kafka provides the following guarantees:
- At least once delivery: Messages are delivered at least once to consumers, meaning duplicates are possible unless handled.
- Ordering within a partition: Kafka guarantees message order within each partition.
- Durability: Messages are written to disk and replicated across brokers, ensuring they are not lost.
- High availability: Through replication and partitioning, Kafka ensures fault tolerance and continued service.
These guarantees make Kafka reliable for building distributed, event-driven systems.
✅ 7. How does Kafka ensure fault tolerance?
Kafka ensures fault tolerance through:
- Replication: Each partition is replicated across multiple brokers. If one broker fails, another replica can take over.
- Leader election: One broker acts as the leader for a partition. If the leader fails, a new leader is automatically elected from the replicas.
- Acknowledgments: Producers and consumers can choose acknowledgment levels to ensure messages are safely written or read.
These mechanisms help Kafka remain highly available and resilient to failures.
✅ 8. What is Kafka Retention Policy?
Kafka Retention Policy controls how long messages are stored in a topic, regardless of whether they’ve been consumed.
There are two main types:
- Time-based: Messages are retained for a set period (e.g., 7 days).
- Size-based: Messages are retained until the log reaches a specified size.
This allows Kafka to manage disk usage while supporting use cases like message replay and long-term storage.
✅ 9. What is the role of the Kafka Broker?
Answer: A Kafka broker is a server that:
- Stores topics and partitions
- Receives data from producers
- Serves data to consumers
- Manages message replication
Each broker has a unique ID and is part of the Kafka cluster.
The following diagram shows a Kafka broker, which acts as an agent or broker to exchange messages between the Producer and the Consumer:

✅ 10. How is data written and read in Kafka?
In Kafka, data is written by producers and read by consumers:
- Producers send messages to a specific topic, which is divided into partitions. Each message is appended to the end of a partition.
- Consumers read messages from partitions in the order they were written. They track their own read position using offsets.
This model enables high throughput, fault tolerance, and scalability.
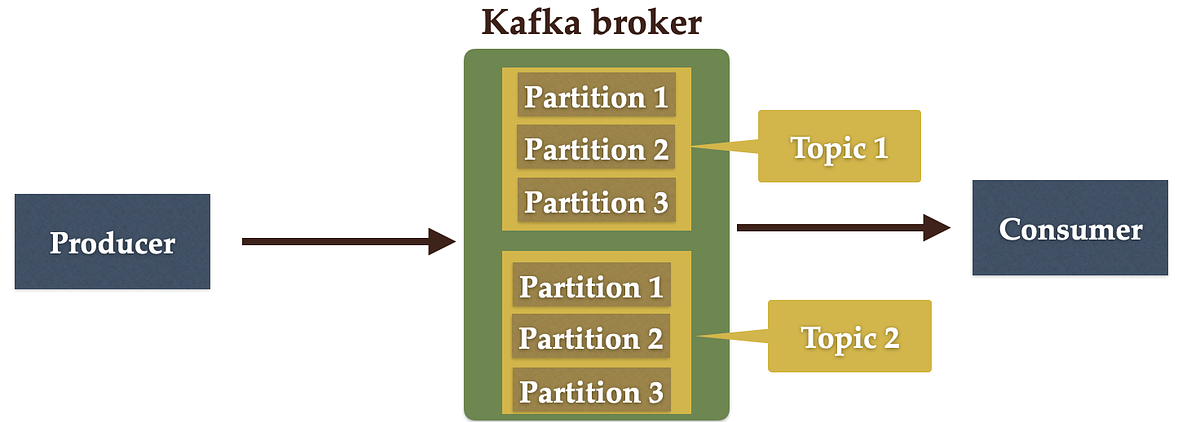
✅ 11. What is Kafka Offset?
The offset is a unique ID assigned to each record in a partition. It represents the consumer’s position in the partition log.
Consumers can commit offsets to track their progress.
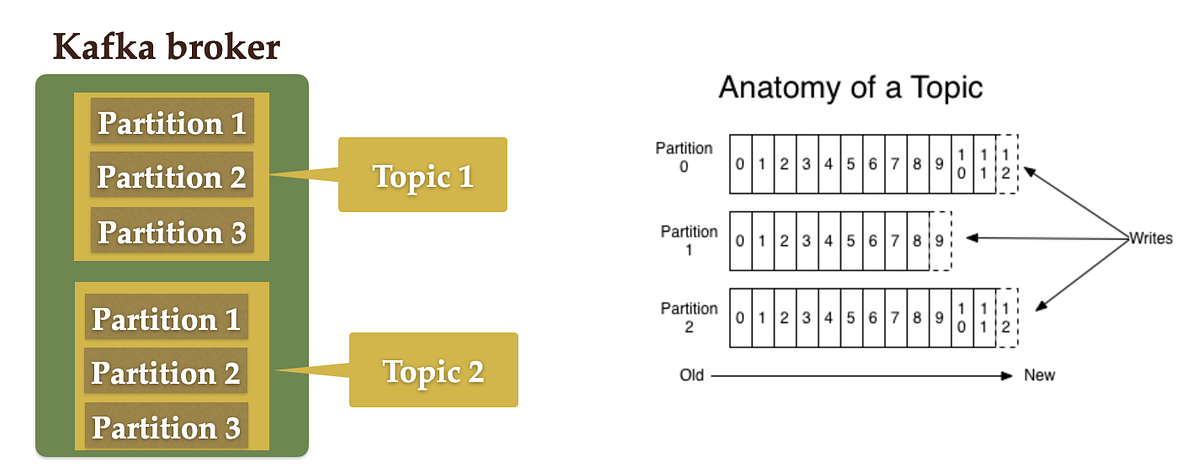
✅ 12. How does Kafka achieve high throughput?
Kafka is optimized for performance using:
- Sequential disk I/O
- Batching
- Zero-copy transfer (via
sendfile) - Asynchronous replication
It can handle millions of messages per second.
✅ 13. What is Kafka Producer Acknowledgment?
The acks config controls how the Kafka producer waits for acknowledgment:
acks=0– No acknowledgmentacks=1– Leader acknowledgment onlyacks=all– Leader + replicas acknowledgment (safe)
✅ 14. What is idempotence in Kafka?
Idempotent producers ensure that the same message is not written multiple times, even if retries happen due to network failures. Use enable.idempotence=true.
✅ 15. What is Kafka Streams?
Kafka Streams is a client-side Java library for real-time stream processing and transformations using Kafka topics.
Supports operations like:
- Map, filter, groupBy
- Windowing
- Joins and aggregations
✅ 16. What is the difference between Kafka and traditional messaging systems?

✅ 17. What is Kafka Connect?
Kafka Connect is a tool to integrate Kafka with external systems (databases, files, cloud services) using pre-built or custom connectors.
Supports:
- Source connectors (e.g., MySQL to Kafka)
- Sink connectors (e.g., Kafka to Elasticsearch)
✅ 18. What is Kafka REST Proxy?
Kafka REST Proxy provides a RESTful HTTP API for producing and consuming Kafka messages, useful for non-Java clients or lightweight applications.
✅ 19. What is the role of a Zookeeper in Kafka?
In older Kafka versions, Zookeeper handles:
- Broker metadata
- Topic and partition info
- Leader election
Newer Kafka versions are migrating to KRaft mode, removing the need for Zookeeper.
✅ 20. What is KRaft in Kafka?
KRaft (Kafka Raft Metadata mode) is a new Kafka mode that replaces Zookeeper and uses Raft protocol for:
- Metadata storage
- Leader election
- Cluster coordination
KRaft simplifies deployment and improves reliability.
✅ 21. What is Kafka’s Exactly Once Semantics (EOS)?
Exactly Once Semantics ensures:
- A message is processed and stored exactly once
- No duplicates
- No loss
Enable with:
- Idempotent producer
- Transactions (
enable.idempotence=true,transactional.id=...)
✅ 22. What is log compaction in Kafka?
Log compaction allows Kafka to retain the latest value for each key, removing older entries. It’s useful for systems like:
- Cache updates
- Latest user profile info
Enable with:
cleanup.policy=compact✅ 23. How do you secure Kafka?
To secure Kafka, you can implement the following measures:
- Authentication: Use SASL (e.g., SASL/SCRAM, SASL/GSSAPI) to verify client identities.
- Authorization: Use ACLs (Access Control Lists) to control what actions users can perform.
- Encryption: Enable SSL/TLS to encrypt data in transit between brokers, producers, and consumers.
- Data integrity: Use SSL to ensure messages are not tampered with.
These security features help protect Kafka from unauthorized access and data breaches.
✅ 24. What is a dead letter queue (DLQ) in Kafka?
A Dead Letter Queue (DLQ) in Kafka is a special topic used to store messages that cannot be processed successfully by a consumer.
If a message repeatedly fails (due to errors like deserialization issues or business logic failures), it’s sent to the DLQ instead of being retried indefinitely. This helps in isolating problematic messages without blocking the processing of valid ones.
Useful when consumers cannot process certain records due to:
- Format errors
- Business rule violations
✅ 25. How is Kafka used in real-world projects?
In real-world projects, Kafka is used to build real-time data pipelines and event-driven architectures. Common use cases include:
- Log aggregation from multiple services.
- Real-time analytics and monitoring.
- Data streaming between microservices.
- Ingesting data into big data systems like Hadoop or Spark.
- Message queuing for decoupling services.
Kafka’s high throughput and fault tolerance make it ideal for handling large volumes of data across distributed systems.
Summary

✅ Final Thoughts
Apache Kafka is not just a messaging system — it’s the backbone of modern data pipelines and event-driven architectures. Mastering its core concepts will open doors in backend development, big data, and real-time analytics.
Practice working with:
- Kafka CLI tools
- Kafka Producer & Consumer APIs
- Kafka Streams & Kafka Connect
Understanding how Kafka works under the hood helps you write scalable, fault-tolerant systems that perform well in production.
My Top and Bestseller Udemy Courses. The sale is going on with a 70 - 80% discount. The discount coupon has been added to each course below:

Build REST APIs with Spring Boot 4, Spring Security 7, and JWT
![[NEW] Learn Apache Maven with IntelliJ IDEA and Java 25](https://img-c.udemycdn.com/course/750x422/6852721_b512_2.jpg "[NEW] Learn Apache Maven with IntelliJ IDEA and Java 25")
[NEW] Learn Apache Maven with IntelliJ IDEA and Java 25

ChatGPT + Generative AI + Prompt Engineering for Beginners
")
Spring 7 and Spring Boot 4 for Beginners (Includes 8 Projects)
Available in Udemy for Business

Building Real-Time REST APIs with Spring Boot - Blog App
Available in Udemy for Business

Building Microservices with Spring Boot and Spring Cloud
Available in Udemy for Business

Java Full-Stack Developer Course with Spring Boot and React JS
Available in Udemy for Business

Build 5 Spring Boot Projects with Java: Line-by-Line Coding

Testing Spring Boot Application with JUnit and Mockito
Available in Udemy for Business

Spring Boot Thymeleaf Real-Time Web Application - Blog App
Available in Udemy for Business

Master Spring Data JPA with Hibernate
Available in Udemy for Business

Spring Boot + Apache Kafka Course - The Practical Guide
Available in Udemy for Business



")

Comments
Post a Comment
Leave Comment